第5节 玩游戏—强化学习算法
DeepMind《Playing Atari with Deep Reinforcement Learning》提出了强化学习算法(DQN),DQN使用卷积神经网络作为价值函数来拟合Q-learning中的动作价值,这是第一个直接从原始像素中成功学习到控制策略的深度强化学习算法。DQN 模型的核心就是卷积神经网络,使用Q-learning 来训练,其输入为原始像素,输出为价值函数。在不改变模型的架构和参数的情况下,DQN在七个Atari2600游戏上,击败了之前所有的算法,并在其中三个游戏上,击败了人类最佳水平。
练习1:Flappy Bird
1.打开项目文件夹learn-ai/codes/chapter2/part6_DQN/DeepLearningFlappyBird
2.打开Anaconda Prompt,执行:
conda activate learn-ai
python deep_q_network.py
执行后将会开始进行模型训练
3.使用预先训练好的模型:
python deep_q_network_trained.py
练习2:进化算法超级马里奥
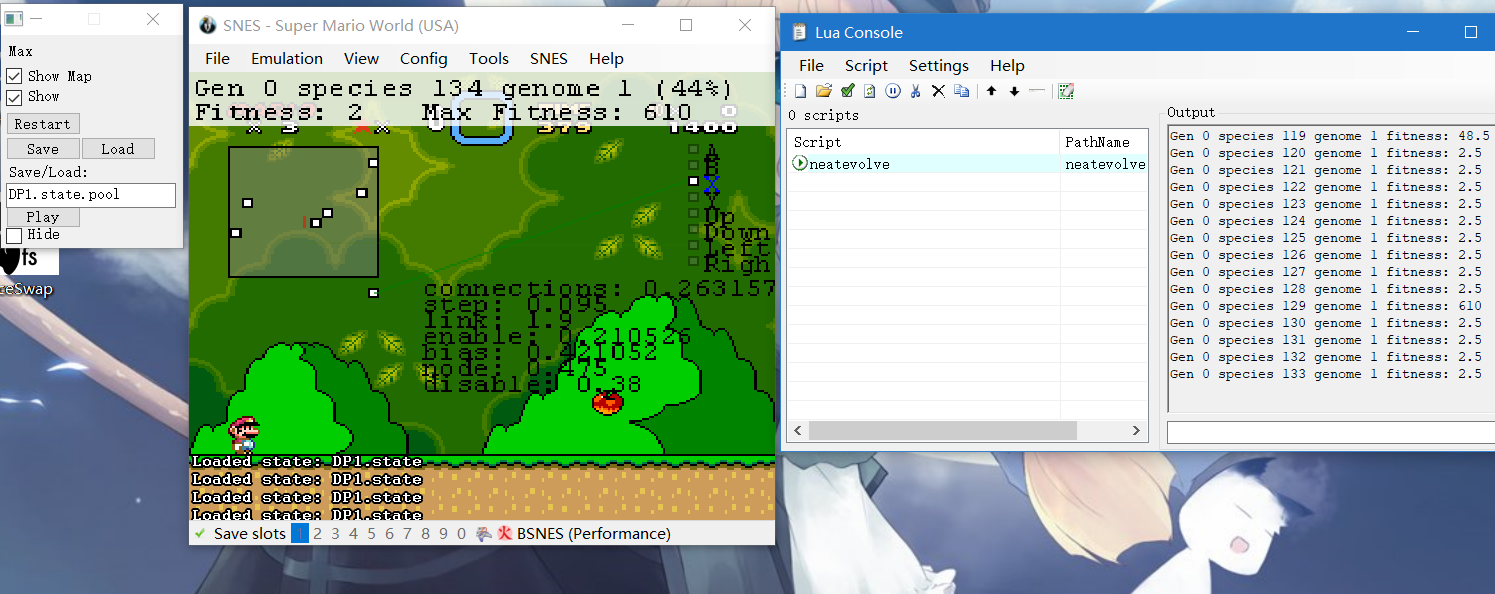
这种学习方式称之为神经网络进化拓扑结构(NeuroEvolution of Augmenting Topologies,简称NEAT)
实际进化过程中,超级马里奥并不会进行预测以改变其行动。通过进行不同的尝试,而不是做其“应该”做的事情,这样每次都会产生新的点子。当一个点子成功后,就会被记住,反之则被作废。就这样,超级马里奥在经历了34尝试后,完全通关了!当然,如果重新运行的话,这套AI机会肯定可以找到一条不同但不会更加成功的线路。
1.打开项目文件夹learn-ai/codes/chapter1/part6_DQN/SuperMario
2.双击打开EmuHawk.exe
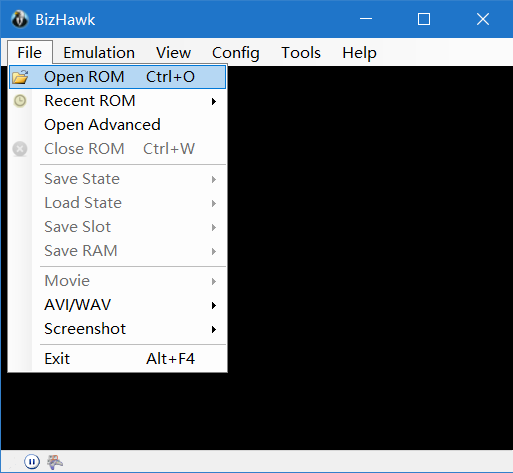
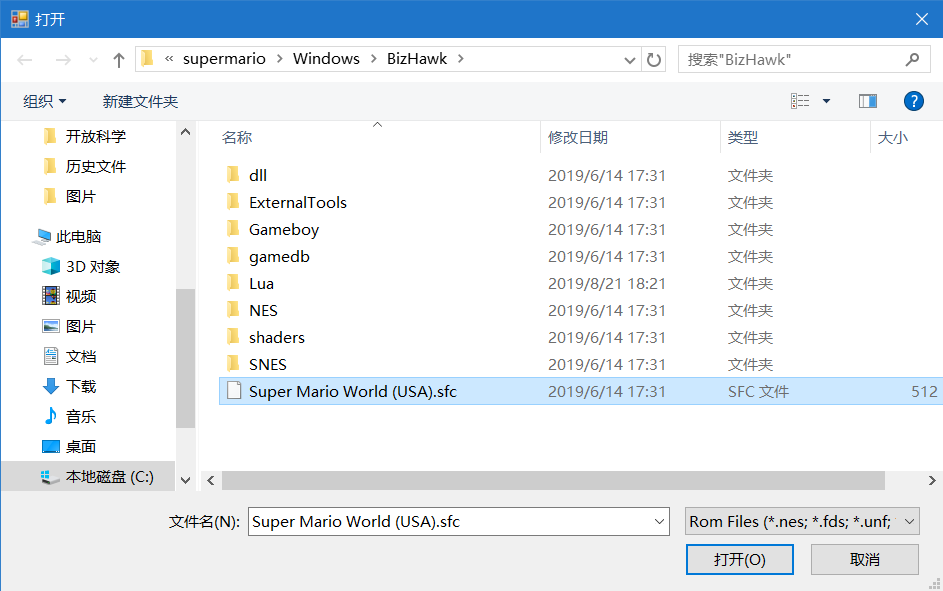
3.载入游戏文件 点击左上角的File——Open ROM,然后选择项目目录下的Super Mario World(USA).sfc
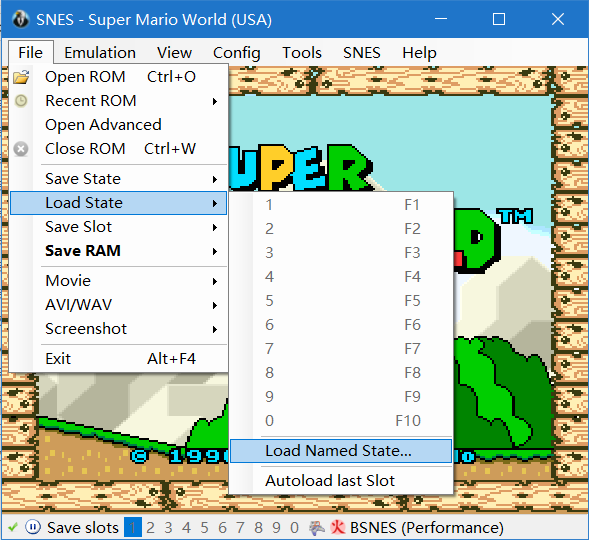
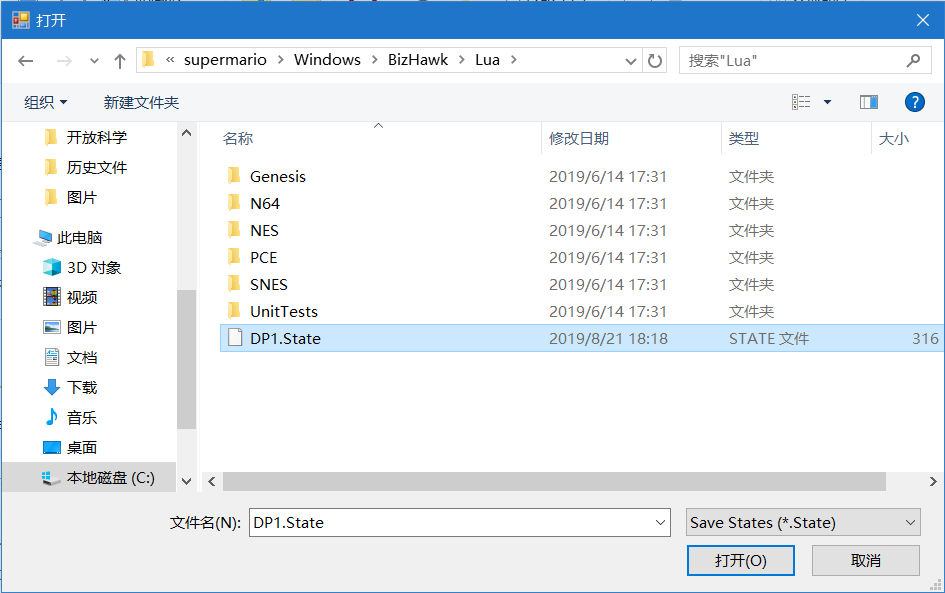
4.载入游戏存档文件 点击左上角的File——Load State——Load Named State,然后选择Lua目录下的DP1.State
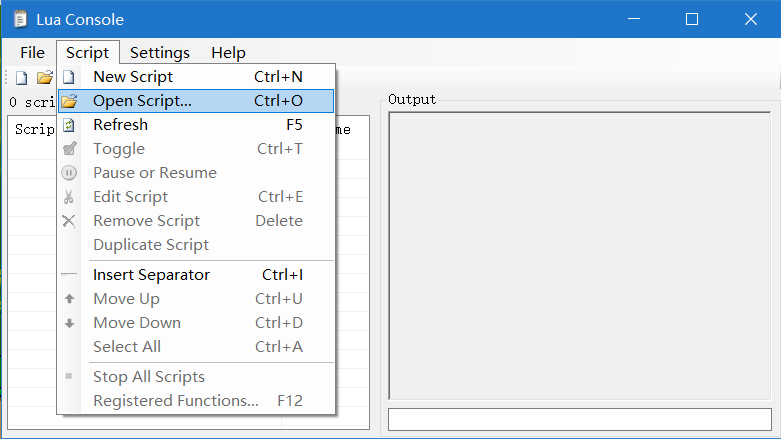
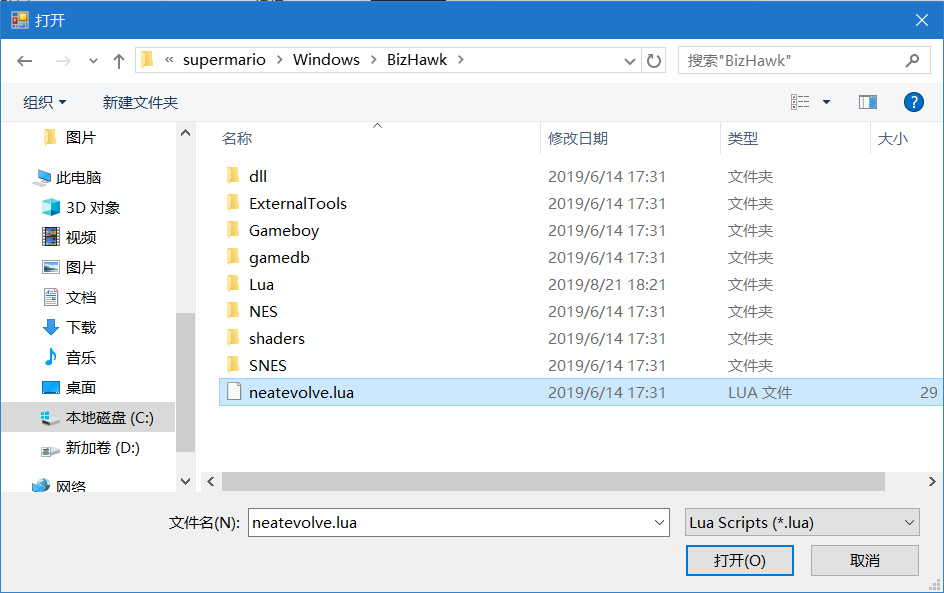
5.载入算法文件 点击左上角的Tool——Tool Box,选择Lua Console。在新窗口中点击Script——Open Script,选择项目目录下的neatevolve.lua
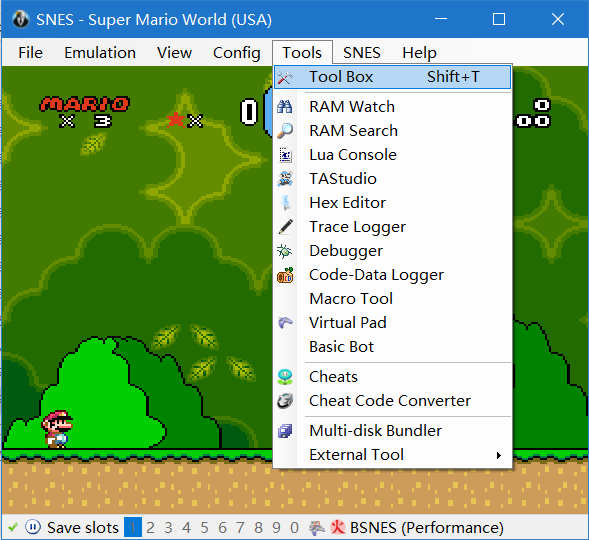
6.观察游戏的自我进化过程 思考游戏进化的过程和生物进化的异同
练习3:头脑游戏—学习你喜欢的颜色
思考一个数组,它从0到255。一个游标,在中间的位置上。一个黄灯和一个绿灯。一个按钮,与游标相连。
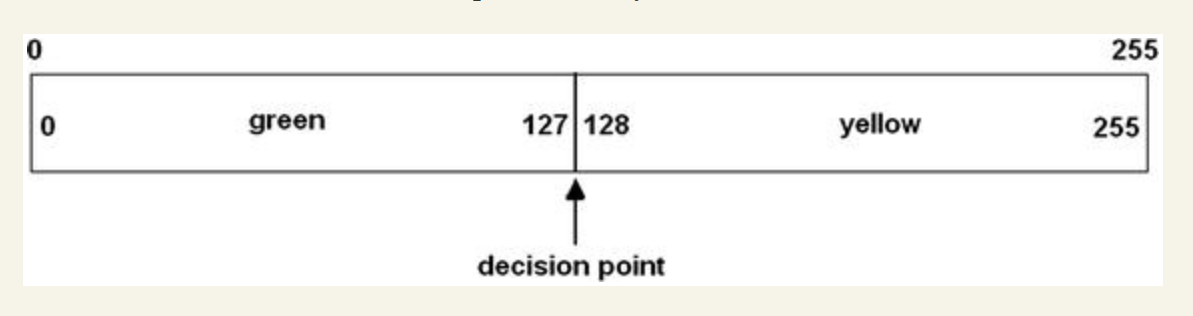
前提设定: 数字每隔1秒在一个随机的位置出现,如果出现在游标左侧,则绿灯亮,如果在游标右侧,则黄灯亮。即黄灯还是绿灯亮完全是随机的。 数组喜欢被你按按钮。
上帝的推动:“你”来了,你更喜欢绿色,这个简单的机器会理解你么?
在每次亮灯时,如果亮了绿灯,你就按一下按钮,表示喜欢。如果亮黄灯,就什么都不做。
数组发现它每次亮绿灯,都会得到奖励(按按钮),本能决定增大绿色的面积,也就是将游标右移,这样落在绿色的概率就更大了。于是,每次它都将游标向右移动1格。
经过一段时间,绿色出现的次数越来越多,它学会了,你的奖励产生了效果。
结语:
超级马里奥的终极目标是在屏幕上向右移动最远的距离,数组游标的终极目标就是不断被按按钮,人类的终极目标是否是将基因一代一代的传递下去呢? 为了这些终极目标,我们学会了趋利避害,一切有利于达成目标的活动都被保留了下来。即使有些时候它甚至是一种迷信:
“沃兹尼亚克发明了一个能够发射出电视机信号的口袋装置。他会带着这个装置走进一个房间,比如宿舍,大家都在那里看电视,而沃兹尼亚克则会悄悄地按下口袋装置的按钮,用静电干扰电视屏幕,让画面变得模糊。只要有人站起来去拍电视机,沃兹尼亚克就会松开按钮,电视屏幕就又恢复清晰。最后,沃兹尼亚克甚至让同学认为,要想恢复画质,必须单脚站立扶着天线,或者摸电视机顶部。